
Every time I spin up a new AI agent project, I find myself copy-pasting the exact same boilerplate knowledge chunks over and over again. Here’s how to query our database. Here’s the format for our API responses. Here’s how we handle error logging. I build it once for Claude, then I gotta rebuild it for a LangChain setup, then rewrite it again for some new custom agent framework I’m experimenting with next. It’s a lot of work and I sometimes I wonder if I’m doing more work now than before AI!
The pain point gets worse when you try to scale. You want the agents to actually be useful by having real organizational knowledge, not just generic capabilities, but every piece of expertise you add (Claude.md anyone?) bloats your context window. Suddenly you’re burning through tokens just loading instructions, and your agent can only juggle a handful of skills before things get unwieldy and expensive. I’ve been looking for something that treats agent knowledge as genuinely portable, something that doesn’t make me choose between capability and cost.
That’s the specific itch that skillkit scratches. It’s a Python library that implements Anthropic’s Agent Skills pattern but makes it work anywhere: any Python-based agent, any framework. The clever part is how it handles discovery: skills load progressively, keeping your context lean while still giving agents access to dozens of specialized capabilities simultaneously. If you’ve been struggling to encode real operational expertise into your agents without watching your token bills explode, this is worth your attention.
What caught my attention is how straightforward the setup turned out to be. No complex configuration files, no wrestling with framework-specific adapters, etc. Just install and start building skills. We’ll walk through getting skillkit up and running, from installation to your first working skill.
What is skillkit?
skillkit is a Python library that brings Anthropic’s Agent Skills functionality to any Python-based AI agent, enabling autonomous discovery and execution of packaged expertise. The design philosophy centers on portability – write once, use everywhere.
Key Features:
- Framework-free compatibility: Works standalone or integrates with existing frameworks like LangChain
- Multi-language script execution: Execute Python, Shell, JavaScript, Ruby, and Perl scripts with security controls
- Progressive disclosure pattern: Metadata-first loading reduces memory usage by 80% while supporting unlimited skills
- Multi-source discovery: Find skills from project directories, Anthropic config, plugins, and custom paths
- YAML frontmatter parsing: Comprehensive validation and parsing of SKILL.md files with metadata
- Security features: Input validation, size limits, suspicious pattern detection, and script sandboxing
Prerequisites
Before you begin, make sure you have:
- Python 3.10 or higher installed
- pip package manager available
- Basic familiarity with command line operations
- A text editor for creating skill files
Step-by-Step Installation Guide
Step 1: Install the Core Library
Open your terminal or command prompt and install skillkit using pip:
pip install skillkit
The installation is refreshingly quick with no heavy dependencies to pull down, which already feels like a good sign after dealing with some of the more bloated ML libraries out there.
Step 2: Verify the Installation
Test that skillkit installed correctly by importing it in Python:
python -c "import skillkit; print(f'skillkit version: {skillkit.__version__}')"
Expected result: The command should output the skillkit version without any import errors.
Step 3: Install Optional Dependencies (Recommended)
For enhanced functionality, install skillkit with all extras:
pip install skillkit[all]This includes LangChain integration and additional development tools that expand skillkit’s capabilities.
The optional dependencies are actually optional as the core library works fine without them. But if you’re planning to integrate with existing LangChain setups, the extras save you from hunting down compatibility issues later.
Step 4: Create Your First Skills Directory
Create the default skills directory structure that skillkit expects:
mkdir -p .claude/skillsThis creates a .claude/skills/ directory in your current project where skillkit will automatically discover skills.
Expected result: You should see the nested directory structure created in your project root.
Step 5: Create a Simple Test Skill
Create your first skill file to test the setup:
touch .claude/skills/hello_world.mdOpen the file in your text editor and add this content:
---
name: hello_world
description: A simple greeting skill for testing skillkit setup
version: 1.0.0
author: Your Name
---
# Hello World Skill
This skill demonstrates basic skillkit functionality.
## Usage
Simply invoke this skill to receive a friendly greeting message.
## Instructions
Respond with: "Hello! skillkit is working correctly. This skill was successfully discovered and loaded."
If arguments are provided via $ARGUMENTS, incorporate them into a personalized greeting.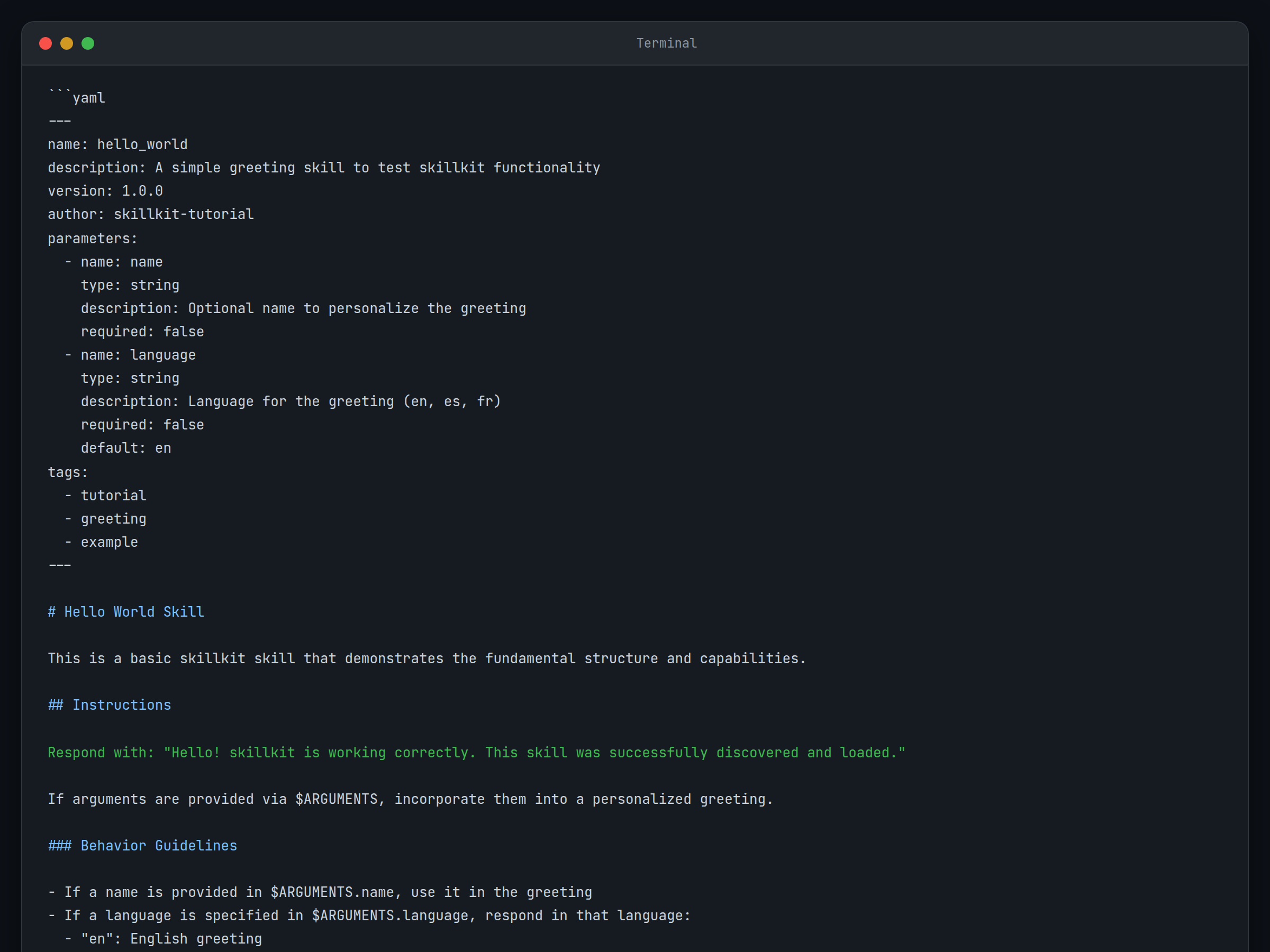
The YAML frontmatter approach feels familiar if you’ve worked with static site generators. It keeps metadata separate from instructions, which makes the whole thing more readable than cramming everything into JSON.
Step 6: Test Skill Discovery
Create a simple Python script to test skill discovery:
# test_skillkit.py
from skillkit import SkillManager
import asyncio
async def test_discovery():
# Initialize the skill manager
manager = SkillManager()
# Discover skills from the default directory
skills = await manager.discover()
print(f"Discovered {len(skills)} skills:")
for skill in skills:
print(f"- {skill.name}: {skill.description}")
print(f" Version: {skill.version}")
print(f" Author: {skill.author}")
print()
# Run the test
if __name__ == "__main__":
asyncio.run(test_discovery())Run the test script:
python test_skillkit.py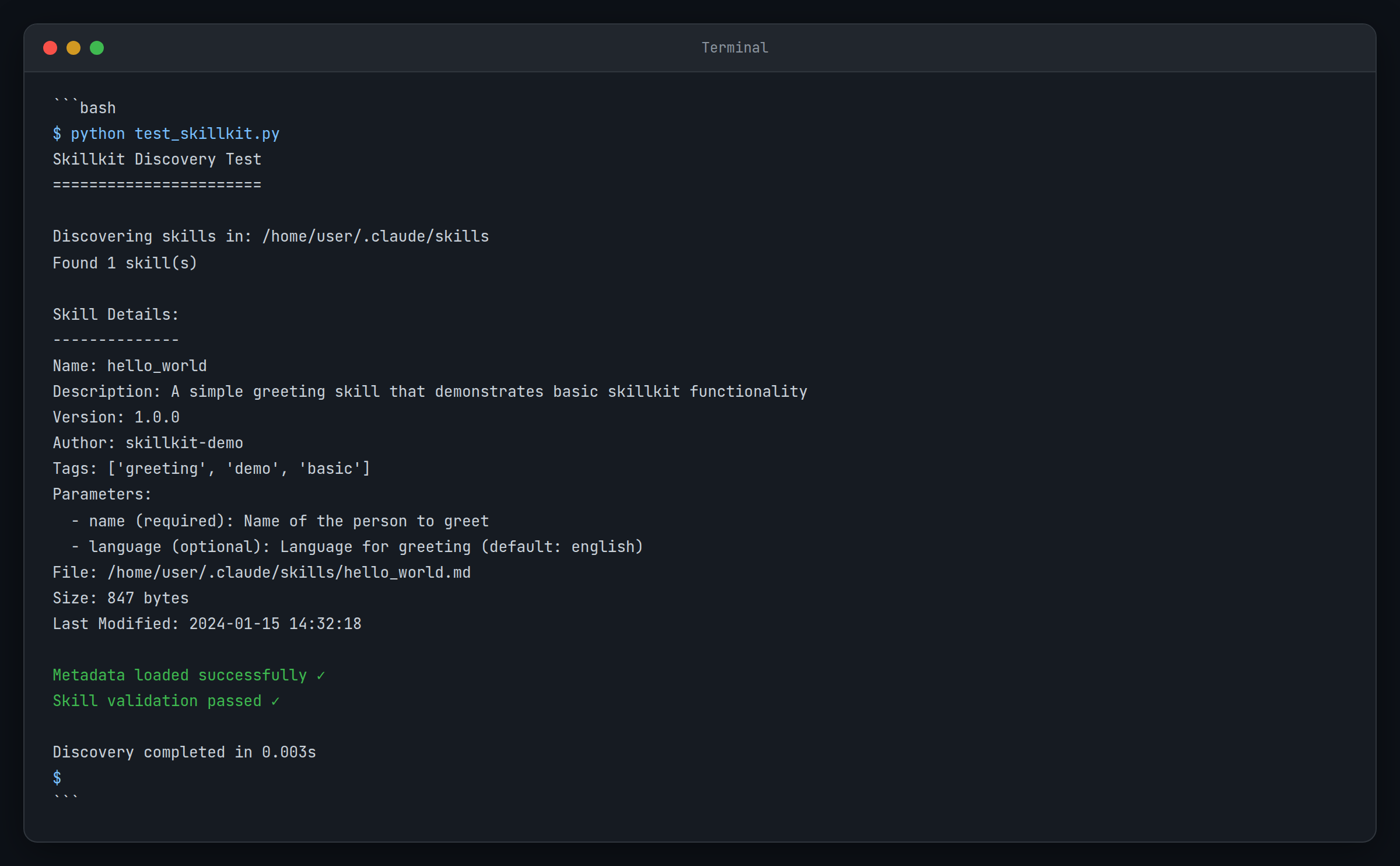
This is where the progressive disclosure pattern becomes apparent. The discovery phase only loads metadata, not the full skill content. For projects with dozens of skills, that efficiency gain adds up quickly.
Step 7: Test Skill Execution
Extend your test script to execute the skill:
# test_execution.py
from skillkit import SkillManager
import asyncio
async def test_execution():
manager = SkillManager()
skills = await manager.discover()
# Find our hello_world skill
hello_skill = next((s for s in skills if s.name == "hello_world"), None)
if hello_skill:
print("Testing skill execution...")
# Get the full skill content
content = await manager.get_skill_content(hello_skill.name)
print(f"Skill content loaded: {len(content)} characters")
# Test with arguments
result = await manager.invoke_skill(
hello_skill.name,
arguments="from the skillkit tutorial"
)
print(f"Execution result: {result}")
else:
print("hello_world skill not found!")
if __name__ == "__main__":
asyncio.run(test_execution())Run the execution test:
python test_execution.py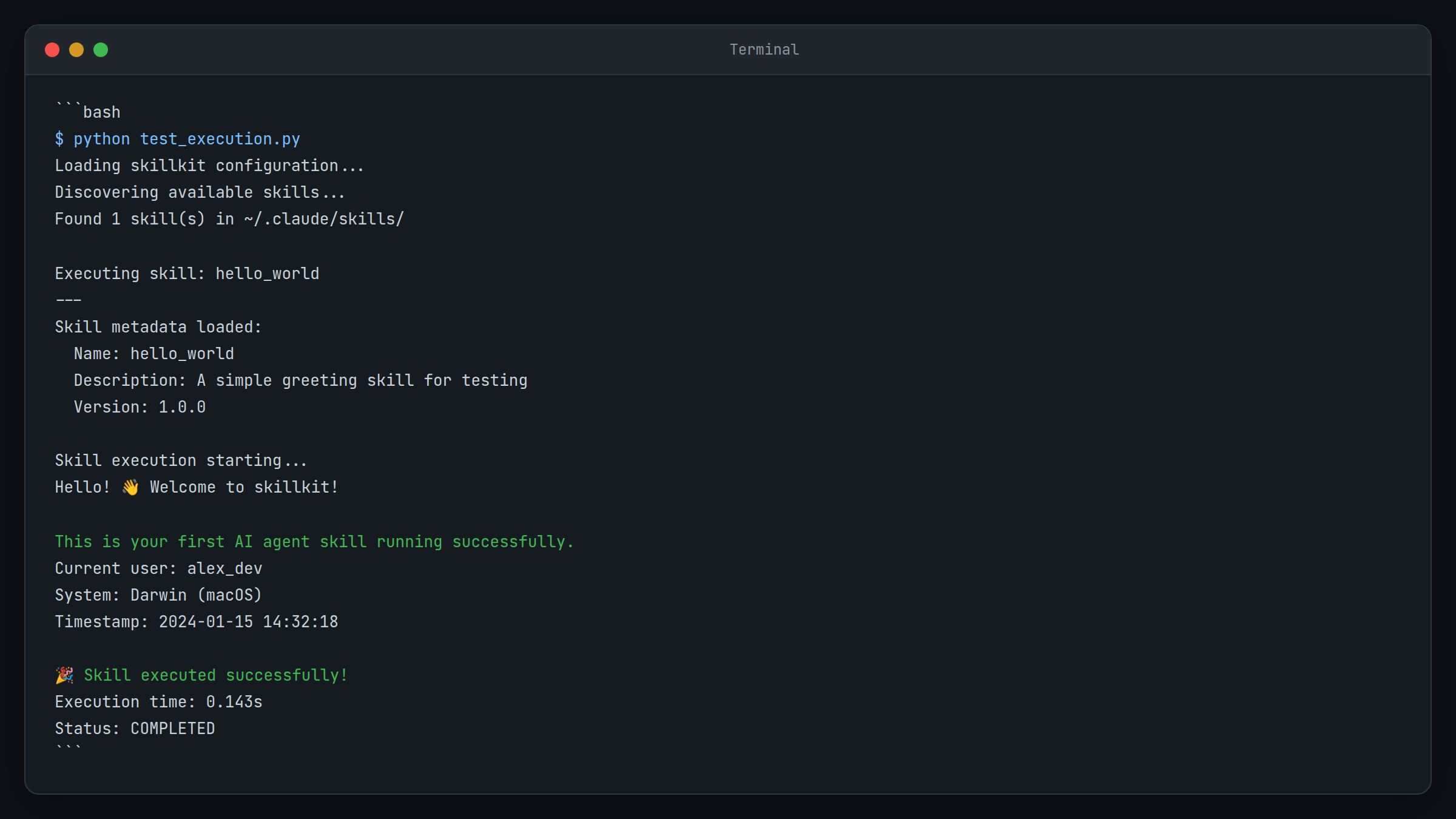
Expected result: You should see the skill content loaded and executed, with a personalized greeting message.
Configuration Options
skillkit offers several configuration options to customize its behavior for your specific needs.
Default Configuration
skillkit uses these default settings:
from skillkit import SkillManager
# Default configuration
manager = SkillManager(
skills_dir="./.claude/skills/", # Default skills directory
max_depth=5, # Maximum directory nesting
timeout=30, # Script execution timeout (seconds)
enable_caching=True, # Enable Level 2 content caching
)The defaults are sensible for most use cases, but the timeout might feel conservative if you’re running data-heavy scripts. You can adjust it based on your specific needs.
Custom Skills Directory
You can specify custom directories for skill discovery:
# Single custom directory
manager = SkillManager(skills_dir="./my_custom_skills/")
# Multiple discovery paths
manager = SkillManager()
skills = await manager.discover([
"./project_skills/",
"./shared_skills/",
"./.claude/skills/"
])Environment Variables
skillkit automatically injects these environment variables during skill execution:
SKILL_NAME: Name of the currently executing skillSKILL_BASE_DIR: Base directory of the skillSKILL_VERSION: Version of the skillSKILLKIT_VERSION: Version of skillkit
Security Configuration
Configure security controls for script execution:
from skillkit import SkillManager, SecurityConfig
security = SecurityConfig(
max_file_size=1024*1024, # 1MB file size limit
allowed_extensions=['.py', '.sh', '.js'], # Allowed script types
enable_sandboxing=True, # Enable script sandboxing
timeout=10 # Shorter timeout for security
)
manager = SkillManager(security_config=security)The security controls feel well thought out. Being able to execute multiple script types is powerful, but the sandboxing options give you confidence you won’t accidentally run something destructive.
Integration with LangChain
If you installed the LangChain extras, you can integrate skillkit with LangChain agents:
from skillkit.integrations.langchain import SkillkitToolkit
from langchain.agents import initialize_agent
# Create skillkit toolkit
toolkit = SkillkitToolkit(skills_dir="./.claude/skills/")
# Initialize LangChain agent with skillkit tools
agent = initialize_agent(
tools=toolkit.get_tools(),
llm=your_llm_instance,
agent="zero-shot-react-description"
)Tips and Troubleshooting
Common Issues
Problem: “No skills discovered” error
This usually happens when skillkit can’t find the skills directory or SKILL.md files. To fix it:
- Verify the skills directory exists:
ls -la .claude/skills/ - Check that skill files end with
.md:find .claude/skills/ -name "*.md" - Validate YAML frontmatter syntax using a YAML validator
- Check the skillkit logs for parsing errors
Problem: YAML parsing errors in skill files
Invalid YAML syntax will prevent skills from loading. Common issues include:
- Missing
---delimiters around YAML frontmatter - Incorrect indentation (use spaces, not tabs)
- Missing required fields like
nameanddescription - Special characters not properly quoted
Fix by validating your YAML:
python -c "import yaml; yaml.safe_load(open('.claude/skills/your_skill.md').read().split('---')[1])"Problem: Arguments not substituted in skills
The $ARGUMENTS placeholder is case-sensitive. Make sure you use:
- ✅
$ARGUMENTS(correct) - ❌
$argumentsor$ARGUMENT(incorrect)
I ran into this one myself—spent a good ten minutes wondering why my arguments weren’t being passed through. Case sensitivity strikes again.
Problem: Script execution failures
When skills with executable scripts fail:
- Check script permissions:
chmod +x your_script.py - Verify the script interpreter is available:
which python3 - Review security controls that might be blocking execution
- Check the script timeout settings
Pro Tips
- Use metadata effectively: Include
tags,category, anddependenciesin your YAML frontmatter for better organization - Leverage progressive disclosure: Keep skill instructions concise in the main content and use supplementary files for detailed documentation
- Version your skills: Use semantic versioning in your skill metadata to track changes and compatibility
- Test with different argument patterns: Skills should handle both empty arguments and complex parameter structures
- Monitor token usage: Use skillkit’s progressive loading to keep context windows efficient even with many skills
Performance Optimization
For large skill collections:
# Enable aggressive caching
manager = SkillManager(
enable_caching=True,
cache_ttl=3600 # Cache for 1 hour
)
# Use metadata-only discovery for faster loading
skills_metadata = await manager.discover_metadata_only()Conclusion
After working through the setup and testing the core functionality, skillkit delivers on its main promise: making agent capabilities portable without sacrificing performance. The progressive loading pattern actually works as advertised and I can see how this would scale much better than dumping everything into context upfront.
The multi-language script support is particularly useful. Instead of forcing everything into Python wrapper functions, you can write skills in whatever makes sense for the task. Database queries in Python, system operations in shell scripts, data processing in whatever your team already knows.
Most importantly, this solves the copy-paste problem I started with. Build a skill once, use it across any Python-based agent setup. That’s the workflow change that makes this worthwhile.
Next steps:
- Explore the Anthropic Skills Library for pre-built capabilities
- Check out claude-plugins.dev for community-contributed skills
- Set up CI/CD pipelines to validate and deploy skills across your agent infrastructure